- Зачем нужна интеллектуальная обработка документов
- Российский рынок интеллектуальной обработки
- Универсальная обработка информации с ContentCapture
- Удобное редактирование с ContentReader PDF
- Линейка продуктов Content AI
Различные технологии автоматизации становятся все более востребованными у российского бизнеса, так как реально позволяют высвободить ресурсы компании и снизить риски человеческого фактора при ручной обработке данных. В то же время растет запрос бизнеса на повышение «уровня интеллектуальности» ИТ-продуктов, который активно подкрепляется расширением возможностей искусственного интеллекта. Обе эти тенденции отражены в интеллектуальной обработке документов – быстро развивающейся сфере технологий, которая имеет обширную область применений.
Зачем нужна интеллектуальная обработка документов
В любой организации работа с документами начинается с первичной обработки: проверки полноты комплекта, занесения документов в учетную систему, заполнения данных в карточках и регистрации. Интеллектуальная обработка позволяет освободить сотрудников от рутинных действий, сэкономить время и минимизировать количество ошибок на этом этапе. При помощи технологий машинного обучения и способности работать с информацией на естественном языке современные решения распознают, классифицируют, извлекают, проверяют и передают по заданным маршрутам данные из любых текстовых сообщений.
Значительную выгоду такие интеллектуальные решения могут принести любой отрасли, ведущей работу с большими объемами входящих и исходящих документов. В их числе ритейл, банки, образование, металлургия, нефтегаз, энергетика, госорганы всех уровней.
К примеру, одной из наиболее распространенных задач в сфере финсектора является обработка документов для открытия счета юридического лица. Далеко не всегда клиенты присылают полный перечень документов в надлежащем качестве. А когда пакет все же собран, его необходимо отсканировать, передать данные в разные программы, проверить по системам противодействия отмыванию денег и финансированию терроризма, зарезервировать счет и создать соответствующую карточку юрлица. При этом риски совершения ошибки оператором в этой сфере имеют крайне высокую цену.
Еще один частотный пример – обработка запросов о предоставлении информации от судов, органов юстиции и прочих государственных ведомств, которые банки получают в огромном количестве. Законом регламентируется срок исполнения в несколько дней, хотя в некоторых случаях ручная подготовка ответа может занимать недели.
Системы интеллектуальной обработки документов, способные анализировать информацию, существенно ускоряют все эти процессы, облегчают труд сотрудников и минимизируют финансовые и юридические риски для организаций.

Пример использования технологических решений можно найти и в сфере образования. Среди студентов и преподавателей широко востребованы редакторы PDF – удобные инструменты для распознавания и редактирования документов разного формата. Во внутренних подразделениях учебных заведений технологии применяются для оцифровки архивов и библиотек. Решения способны распознавать текст, несмотря на низкое качество бумаги и необычные шрифты, а также самостоятельно формировать удобные цифровые хранилища с возможностью морфологического поиска. Кроме того, интеллектуальная обработка документов используется при зачислении абитуриентов и проверке результатов государственных экзаменов.
Для других отраслей современные решения для интеллектуальной обработки информации предлагают широкие возможности сравнения документов, сверки по базам данных и другим источникам, поиска упоминаний компании в СМИ и, более того, определения их тональности.
Российский рынок интеллектуальной обработки
Среди ушедших в 2022 году с российского рынка компаний были и лидеры в области интеллектуальной обработки информации – ABBYY и Kofax. Причем ABBYY занимала большую часть корпоративного сектора. Однако жизнеспособность в этом сегменте сохранилась, поскольку команда топ-менеджмента бывшего российского офиса ABBYY создала независимую компанию Content AI. Кроме осуществления технической поддержки по продолжающим действовать лицензиям ABBYY, Content AI стала развивать собственные продукты с акцентом на потребности российских пользователей.
Технологии, используемые для новых продуктов, были созданы в России и развивались здесь на протяжении 30 лет, положив начало отечественной отрасли распознавания данных и интеллектуальной обработки информации. При этом, имея все необходимые знания о продуктах ABBYY, Content AI обеспечивает плавный переход на отечественное ПО без остановки бизнес-процессов своих заказчиков.

Помимо решений Content AI, на рынке можно найти много продуктов, способных выполнять несложные задачи по типу чтения банковских карт, паспортов и QR-кодов. Однако системы Content AI отличает возможность не только распознавать данные, но и обрабатывать их по различным сценариям. Программа сама программа извлекает необходимую информацию из документов и формирует базу для принятия управленческих решений.
Приоритет команды Content AI – импортозамещение, поэтому ключевой задачей для компании стало включение основных продуктов для интеллектуальной обработки данных — ContentCapture, ContentReader PDF и ContentReader Engine – в реестр отечественного ПО. Следующим шагом стала адаптация продуктов к операционным системам на базе Linux и их совместимость с другими российскими ИТ-решениями.
Универсальная обработка информации с ContentCapture
Один из основных продуктов Content AI ― ContentCapture, универсальная платформа для интеллектуальной обработки информации, заменяющая продукт ABBYY FlexiCapture. Программа относится к разряду общесистемного ПО, так как представляет собой комплексное решение для обработки финансовых, юридических, бухгалтерских документов и т.д.
Продукт комбинирует различные технологии и автоматически подбирает лучшие алгоритмы. Изображения классифицируются с помощью машинного обучения, а текст – с помощью семантического и статистического анализа. При этом решение содержит механизмы автообучения и само учится извлекать данные, учитывая результаты работы верификаторов.
Все это позволяет классифицировать любые типы входящих документов по содержанию, внешнему виду и расположению отдельных элементов. В едином потоке ContentCapture способна одновременно обрабатывать разные форматы документов: фото, тексты, отсканированные бумаги и PDF-файлы, полученные из различных источников ― от электронных писем до МФУ и мобильных устройств.
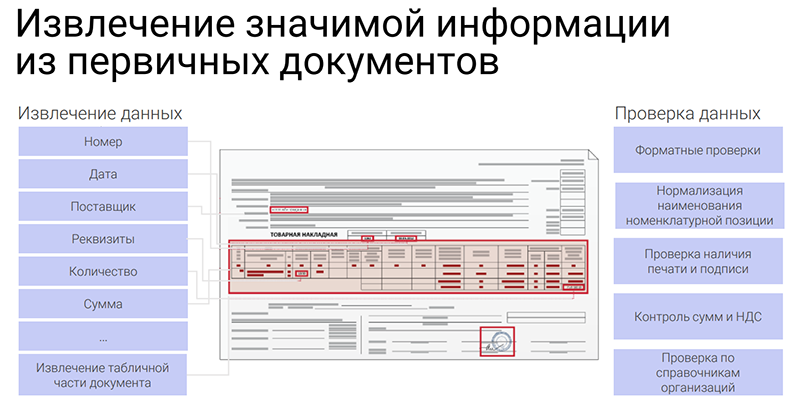
Обширная функциональность продукта дает возможность выполнять разнопрофильные задачи. К примеру, при обработке финансовых и бухгалтерских документов система проверяет полноту комплекта, сверяет наименования со справочниками организации, проверяет наличие подписей и верность расчетов. При автоматизации закупочной деятельности предусмотрена проверка соответствия заявки конкурсному ТЗ и извлечение атрибутов для подготовки заключения по проанализированным заявкам. Кроме того, ContentCapture применяется при работе с кадровыми документами и информационно-аналитической или юридической базой.
Основное назначение ContentCapture – высокопроизводительная потоковая обработка документов. К примеру, оператор федеральной электронной площадки AO «ТЭК Торг» с помощью платформы ContentCapture обрабатывает около 500 тысяч страниц закупочной документации в год. На один документ уходит менее минуты.
В целом, платформа способна обрабатывать до трех миллионов страниц в день, что позволяет значительно экономить время сотрудников. При изменении интенсивности поступления документов производительность легко масштабируется, настройки решения позволяют контролировать работу всех станций и операторов в распределенной структуре. Потоковая обработка легко вводится в рабочие процессы компании благодаря поддержке интеграции с решениями класса ECM, CRM, RPA, АБС и т. д.
Удобное редактирование с ContentReader PDF
Другой флагманский продукт Content AI ― ContentReader PDF, многофункциональный редактор PDF-документов, полностью заменивший известный FineReader PDF. Решение сохранило все возможности предшественника: оно умеет распознавать, редактировать и конвертировать PDF-документы в различные форматы. По сути, программа позволяет сотрудникам работать с PDF так же удобно, как и с любыми текстовыми документами. Причем не только с русскоязычными, но и с многоязычными, так как редактор может распознавать 198 языков.
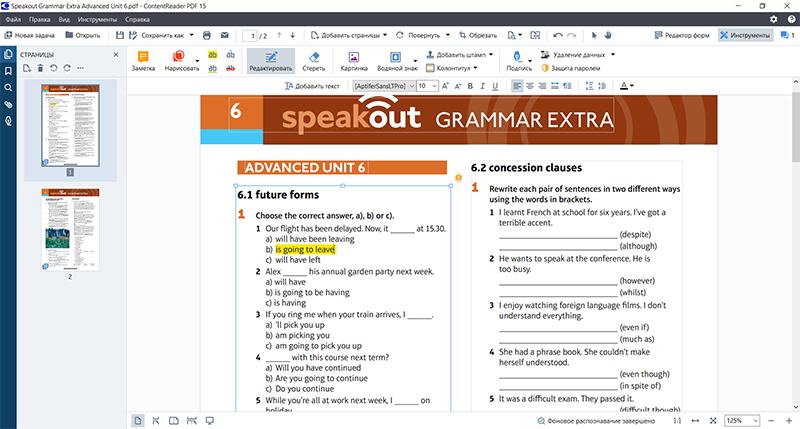
Благодаря уникальным технологиям, включающим оптическое распознавание текста, а также обработку и анализ файла, документ и его структура воспроизводятся максимально точно, включая даже такие сложные элементы как таблицы. При этом система автоматически улучшает качество распознавания сканов, настраивая яркость или удаляя искажения. Внести правки можно прямо в тексте файла либо конвертировать в полностью редактируемый формат без каких-либо потерь.
Помимо редактирования, продукт предоставляет и другие возможности: просмотр и удаление комментариев и метаданных, добавление страниц, создание форм с текстовыми полями, кнопками, опросниками и раскрывающимися списками. Также пользователь может создать новый PDF-документ, объединив файлы других форматов, а затем заверить его цифровой подписью или защитить паролем. При этом работать с документом могут совместно несколько сотрудников.
Продукт имеет функцию поиска по ключевым словам и закладкам, что позволяет находить нужную информацию даже в сканах. Кроме того, ContentReader PDF способен сравнивать документы разных форматов и автоматизировать однотипные задачи по оцифровке и конвертации. В целом решение включает в себя более 100 инструментов для работы с PDF-документами, что обеспечивает его лидирующую позицию в отрасли.
Так же, как и ContentCapture, ContentReader PDF находит применение во многих областях. К примеру, с его помощью офис-менеджеры обрабатывают входящую корреспонденцию и создают шаблоны, маркетологи и аналитики согласовывают отчеты и макеты или готовят и публикуют PDF-документы. Научные сотрудники смогут создавать электронные копии статей и учебных материалов и формировать документы на основе информации из разных источников. А юридическим службам будет проще сравнивать разные версии документов, подписывать и защищать электронные версии и удалять конфиденциальную информацию.

Линейка продуктов Content AI
Помимо обработки документов и редактирования PDF, продукты Content AI используются и для других задач .
Content AI Intelligent Search представляет собой готовое решение для создания корпоративного поискового портала. Благодаря готовым коннекторам к различным корпоративным системам, а также удобным инструментам для интеграции, решение позволяет настроить корпоративный сквозной поиск по всем данным в организации. Помимо сетевых папок и wiki-системы Confluence, продукт может интегрироваться с трекером задач Jira, каталогом пользователей на базе Active Directory и СУБД, из которых благодаря системе можно легко извлечь любую информацию.
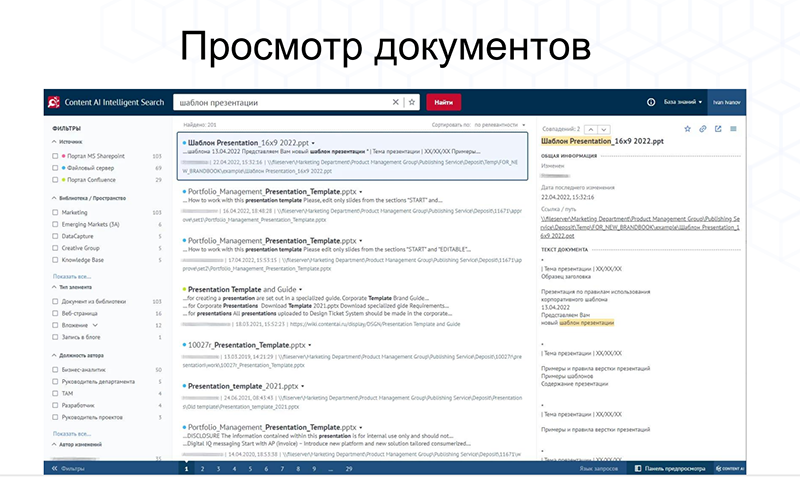
Интеллектуальные технологии также позволяют осуществлять поиск не только по точному запросу, но и по смыслу. Так, например, если сотрудник введет в строку поиска «договор», то также получит результаты со словами «agreement» или «контракт».
Программа включает инструменты аналитики и способна оценивать различные параметры и состояния на основе результатов поиска. Например, на основе данных каталога пользователей Content AI Intelligent Search может построить графический отчет по «текучке кадров» в разных отделах и динамически отслеживать изменения. Мониторить можно и конкретный поисковый запрос с помощью подписки. Система будет сама информировать о поступлении новых документов и присылать уведомления об изменениях, вне зависимости от того, с каким источником они связаны.
Lingvo by Content AI — электронные словари для изучения иностранных языков, которые развиваются с начала 90-х годов. В многоязычной профессиональной версии продукта содержатся 90 словарей для 10 языков.
ContentReader Engine — многофункциональный OCR SDK для разработчиков. По сути это «движок», на базе которого можно создавать собственное ПО или встроить в свои решения функциональность распознавания текстов, классификации изображений и сравнения документов. Его используют, к примеру, в модуле потокового ввода данных в СЭД «ДЕЛО» ― продукте ведущего российского разработчика систем управления документооборотом, электронными и бумажными архивами ЭOC. SDK обеспечивает распознавание печатного текста, штрих-кодов, меток и машиночитаемых (MRZ) зон.
Получайте новые статьи моментально в Telegram по ссылке: https://t.me/sldonline_bot.