Сегодня компании всех отраслей ежедневно сталкиваются с непрекращающимся ростом объема данных, особенно это касается финансового и логистического сектора. Понятно, что с увеличением этих объемов снижается скорость доступа к данным. Руслан Махмудов, ведущий разработчик Центра Высоких Технологий (ЦВТ) группы компаний Softline, дал рекомендации, позволяющие ускорить работу с СУБД и уже с самого начала не допустить критических ошибок, которые могут приводить не только к замедлению всей системы, но и потере важной информации.
Примечание: все советы относятся к ситуациям, когда данных уже накопилось очень много, но до того, что называется Big Data, ещё далеко. Потому что Big Data — это область со своими СУБД, правилами и законами, там многое из того, что есть в нижеследующем материале, не работает или не имеет смысла.
- Текстовые файлы. Когда пока не нужна СУБД?
- Ограничения у текстовых файлов
- СУБД + ORM: когда не надо ошибаться уже с первого шага
- Ограничения NoSQL на примере проекта федеральной сети в г. Воронеж
- Когда на самом деле нужна NoSQL СУБД?
- Неявная денормализация
- Float/double для финансового сектора
- Неподходящие типы данных
- Хранение чисел в виде строки
- 0 или “” вместо NULL
Текстовые файлы. Когда пока не нужна СУБД?
Когда вы пишите приложения, стоит задуматься о том, чтобы вообще не использовать СУБД. Например, если вам нужно хранить небольшой объем аккаунтов пользователей (логин, пароль, ФИО), номенклатуру товаров, справочники, редактировать которые приходится крайне редко, то для этого необязательно всегда заводить базу — вы можете работать с текстовыми файлами. Существует большое множество хорошо «перевариваемых» форматов (JSON, XML, YAML, CSV, INI) и есть функциональные текстовые редакторы, в которых удобно работать (подсветка, удобный поиск, замены). Если объемы данных небольшие (десятки-сотни мегабайт), то их можно считать в кэш-память и легко и быстро с ними работать — вам не надо будет делать запросы в базу. Эти данные легко поддаются бэкапированию. Кроме того, текстовые файлы могут храниться локально, а в случае с СУБД приходится делать запрос на сервер, соответственно, если падает сеть, то работа приостанавливается, а в случае с текстовыми файлами работу можно продолжать, потому что к ним есть локальный доступ. СУБД требует выделенного сервера и постоянного его обслуживания. В случае же с текстовыми файлами вы тратите меньше ресурсов, тем самым работаете эффективнее, а клиент теряет меньше прибыли.
Ограничения у текстовых файлов
Если файлы очень большие, то редактировать их неудобно, особенно если это приходится делать часто. В ситуациях, когда вы вынуждены делать свою работу самостоятельно за какую-то СУБД и оперировать сложными выборками с фильтрами, про текстовые файлы нужно забыть и принимать решение в пользу СУБД. Но если перед вами стоит задача написать простое приложение, возможно, не стоит ставить ORM и выбирать СУБД, ведь в любом языке программирования предусмотрены библиотеки, чтобы собирать любые данные и легко их редактировать.
СУБД + ORM: не надо ошибаться с первого шага
Подавляющее число проблем, которые всплывают в работе с данными, закладываются на ранних этапах, когда программист выбирает СУБД и ORM и начинает строить модели. К сожалению, зачастую программисты делать этого нормально не умеют. Существует огромное количество проектов, которые испытывают все большие проблемы с данными по мере своего роста, поскольку большое количество ошибок было совершено разработчиками еще на этапе проектирования. В середине нулевых годов изобрели NoSQL-базы данных, и огромное количество людей ударились в эксперименты с ними. Мне сразу показались странными некоторые вещи: например, скриншот взят из самой популярной СУБД MongoDB, на нем видно, что люди на самом деле работают с реляционными структурами. Большое количество тьюториалов, которые встречаются в интернете, были написаны по следующей схеме: сейчас мы возьмем MongoDB, будем вставлять туда JSON-документы, и у нас всё будет работать быстро и красиво. Но видно, что они вставляют туда реляционные JSON-данные, например, каталоги каких-нибудь фильмов. Да, это будет нормально работать, но только первое время. Если строится система, которая предусматривает постоянное накопление данных, то рано или поздно мы столкнемся с тем, что эти реляционные структуры и обрабатывать надо будет по-реляционному, и тут JSON не поможет — проект будет похоронен уже на этапе выбора СУБД.
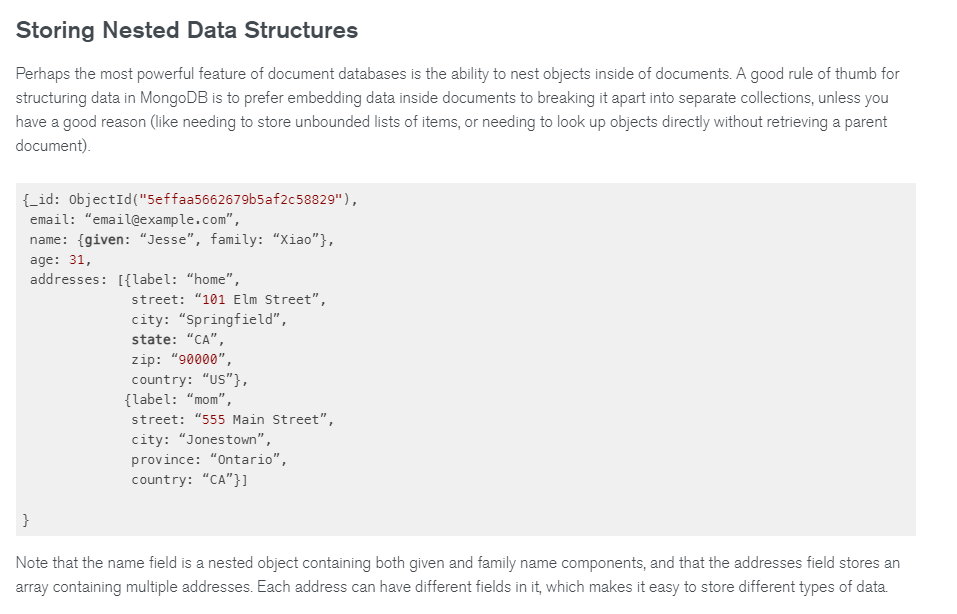
Пример реляционных структур из MongoDB
Ограничения NoSQL на примере проекта федеральной сети в г. Воронеж
Разработчики на самом раннем этапе проекта выбрали MongoDB. Но они использовали её неправильно: данные, которые в ней хранили, всё равно оставались, по сути, реляционными. Бизнес-логика приложений работала с ними как с реляционными, а MongoDB в этом плане сильно уступает реляционным СУБД. И когда база выросла до сотен гигабайт, разработчики столкнулись с проблемой — дальше повышать производительность было невозможно, потому что работа с данными занимала очень много времени. DevOps-специалист этой фирмы рассказывал, что в тот момент денег было достаточно. Они просили сторонние компании обработать какие-то данные, когда это требовалось сделать быстро, но никто не мог. Не помогало ничего — ни добавление серверов, ни шардинг, потому что разработчики в самом начале ограничивались NoSQL. Руслан Махмудов, опираясь на собственный опыт, утверждает, что NoSQL-базы действительно показывают хорошие результаты в разных бенчмарках, но у них ограниченная область применения.
Когда на самом деле нужна NoSQL СУБД?
Нечто неструктурированное, например, логи, можно хранить в NoSQL. Если вы работаете с сырыми данными (показания датчиков, терминалов), можете также складывать их в NoSQL. Есть еще пара случаев, когда NoSQL хороша, но в подавляющем большинстве вы все равно будете работать с реляционными структурами. Современные реляционные СУБД умеют эффективно взаимодействовать с JSON, в том числе делать по ним поиск и индексирование.
Критические ошибки
Неявная денормализация
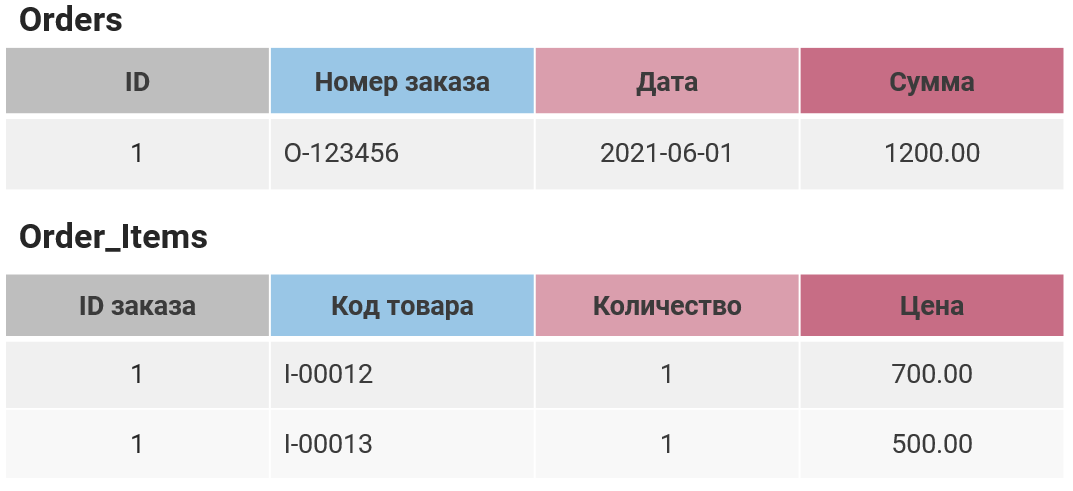
Синтетический кейс, который встречается довольно часто: создается таблица для какого-нибудь заказа, в котором есть поле «Сумма заказа». Тем не менее у этих заказов в другой таблице есть конкретная расшифровка по позициям, и, если эти позиции сложить, тоже получится сумма заказа. И вроде всё нормально, но рано или поздно суммы в двух таблицах разойдутся по самым разным причинам, потому как функционал приложения обязательно будет усложняться и будут появляться какие-то новые условия (скидки, партнерские программы, возвраты товаров). Эти проблемы характерны для сферы продаж. После этого недовольные клиенты начнут жаловаться на то, что у них не сходятся суммы, а исправить это будет сложно, так как эти цифры будут фигурировать по всей базе. Вы начнете терять деньги.
Float/double для финансового сектора
Если вы работает с деньгами, никогда не используйте такие типы данных, как float/double. Они и называются по-русски «типы данных с плавающей точностью». На скриншоте несколько примеров, когда вы ожидаете, что получится одно значение, а выходит другое: обыкновенное вычитание двух простых чисел приводит к неточному результату. У этих вещественных типов значений есть проблема округления, и их никогда не следует использовать, если вы работаете с деньгами, потому что рано или поздно к вам обратится бухгалтер с вопросом, почему у него суммы расходятся, и уже не на копейки, а на рубли. . Для того, чтобы работать с финансами, в каждой СУБД, языке программирования есть свой специальный тип, у которого таких проблем с округлением нет.

Неподходящие типы данных
Разработчики порой используют совершенно неподходящие типы данных для хранения каких-либо значений. До сих пор встречаются типы данных, которые хранятся в виде строки (на скрине): "12.06.01" — это 12 июня 2001 года или 6 декабря 2001 года? Из-за таких вещей бизнес-логика приложения обрастает огромным количеством проверок, и все равно в каком-нибудь месте возникает ошибка. Использование чаров типа «Y» и «N» для того, чтобы отмечать какое-то бинарное значение неправильно, лучше применять тип boolean со значениями true/false, потому что рано или поздно кто-то ошибется и напишет «y» с маленьким регистром или не в той раскладке, и искать причину поломки потом придется очень долго.
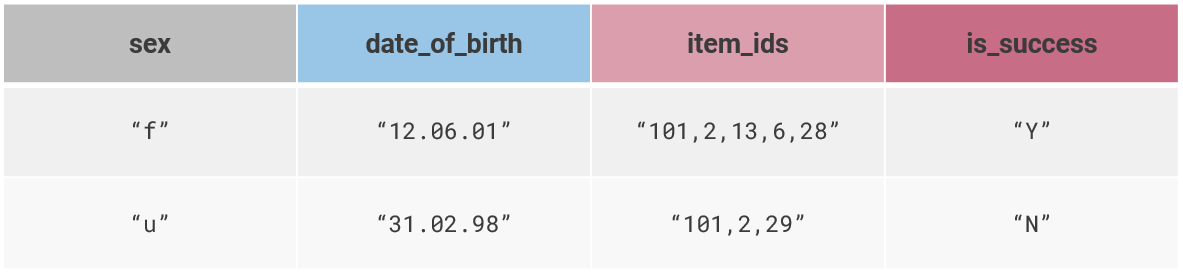
Хранение чисел в виде строки
Встречается регулярно. Люди умудряются хранить в виде строки номера телефонов ИНН, СНИЛС, БИК и другие данные, которые по сути являются числами. Числом также являются паспортные данные в РФ, реквизиты документов и даже банковские счета. Хранение в строке — это перерасход ресурсов, и это еще куда ни шло. Самое страшное, что люди порой хранят данные в отформатированном виде, и это непозволительная ошибка не только при работе с базой данных, но и при программировании. Любое приложение, которое мы пишем, состоит из трех звеньев: уровень представления, бизнес-логики и работы с данными. Между этими уровнями должна быть изоляция, чтобы одно в другое не перетекало. Но когда у вас в базе данных значения хранятся так, как нужно для уровня представления, получается, что мы перескакиваем через целый уровень.

Руслан Махмудов: «Приведу в пример кейс, когда мы вынуждены были хранить номера телефонов в строке в четком виде "+7xxxxxxxxxx" — именно так, строка с плюсом в начале и 11 цифр за ним. В соответствующей таблице под это был отведен тип поля varchar длиной ровно 12 символов согласно бизнес-требованию. На таблице с десятками миллионов записей это был дикий перерасход ресурсов, плюс по номеру телефона часто проходил поиск. Куда выгоднее было бы перевести всё в число, после чего скорость работы запросов увеличилась бы при одновременном уменьшении объёма данных. Мы пытались уговорить заказчика на рефакторинг, но, когда подсчитывали трудозатраты, этот вопрос постоянно отодвигался. Однажды к нам пришли клиенты из Финляндии, где телефонные номера начинаются с +3, и в них 13 символов. В итоге мы в нашу базу загрузили клиентов из Финляндии без номеров телефонов, и в один момент потеряли их всех. Пришлось как-то выкручиваться.
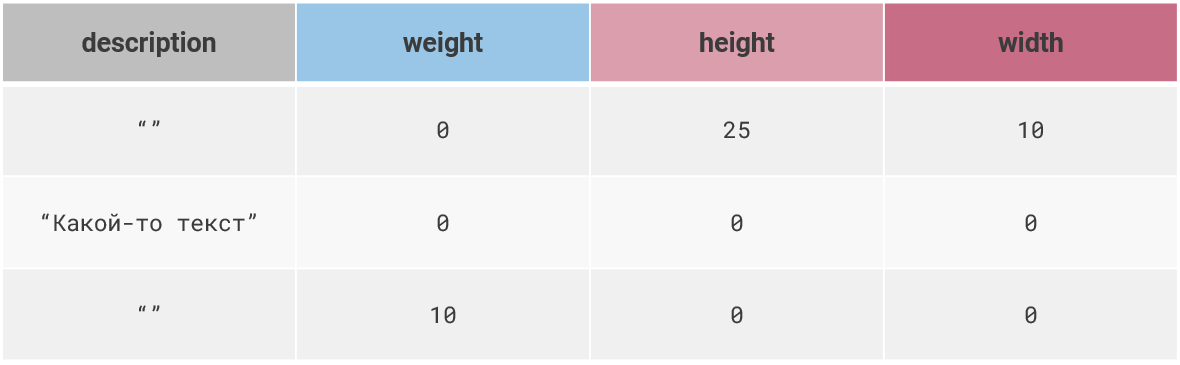
0 или “” вместо NULL
Программисты иногда не умеют настраивать маппинг в ORM, и когда у них нет каких-то данных, в базе появляются значения 0 или пустая строка. Но надо понимать, что 0 — это тоже значение. С точки зрения здравого смысла, если вы не знаете какое-то значение, у вас должен стоять NULL. Если вы будете хранить нули или пустые строки в тех местах, где якобы данных нет, рано или поздно при изменении какого-либо контекста, усложнении бизнес-логики, вы просто не будете понимать, является ли ноль реальным значением или означает отсутствие данных.