
Companies from all sectors, especially financial and logistics, have to process more and more data every day. It is evident that when volumes increase, the data access becomes slower. Ruslan Makhmudov, a Lead Developer of the High Technologies Center (HTC), which is part of the Softline Group, will give his advice on how to speed up the work with the DBMS and prevent critical errors that can not only slow down the entire system but also lead to the loss of important information, at the earliest stages.
Note: all recommendations refer to situations where a lot of data has been already accumulated, but Big Data technologies have not been implemented. That is because Big Data is a field with specific databases, procedures, and rules, and much of what we tell hereinafter does not apply or does not make sense there.
- Text files. When is DBMS not needed yet?
- Limitations of text files
- DBMS + ORM: when you must avoid errors from the very first step
- Limitations of NoSQL on the example of a project for a federal retail chain in Voronezh
- When is a NoSQL DBMS really needed?
- Implicit denormalization
- Float/double for the financial sector
- Inappropriate data types
- Storing numbers as a string
- 0 or “” instead of NULL
Text files. When is DBMS not needed yet?
When you develop applications, not using a DBMS at all is a possible option. For example, if you need to store a small number of user accounts (login, password, full name), a range of products, catalogs, which edit very rarely, then you do not always have to create a database for this —you can just work with text files. There are many machine-friendly formats (JSON, XML, YAML, CSV, and INI) and there are user-friendly text editors with all the required functions—highlighting, easy search, replacements. If the amount of data is small (tens to hundreds of megabytes), then they can be read into cache memory, from which you can quickly and easily access them without even making database queries. This data can be easily backed up. In addition, text files can be stored locally. When you use a database, you have to query the server every time, and if the network goes offline, the work becomes impossible. As for locally available text files, you can work without interruptions. A database requires a dedicated server and ongoing maintenance. In the case of text files, you spend fewer resources, thereby working more efficiently, and the customer loses less profit.
Limitations of text files
If the files are very large, then editing them becomes inconvenient, especially if you have to do it very often. In cases when you need to perform some operations that usually require a database, like operating with complex selections of filters, you need to forget about text files and opt for a database. But if you have to develop a simple application, perhaps you should not install an ORM and choose a database, because any programming language provides libraries to collect any data and easily edit it.
DBMS + ORM: when you must avoid errors from the very first step
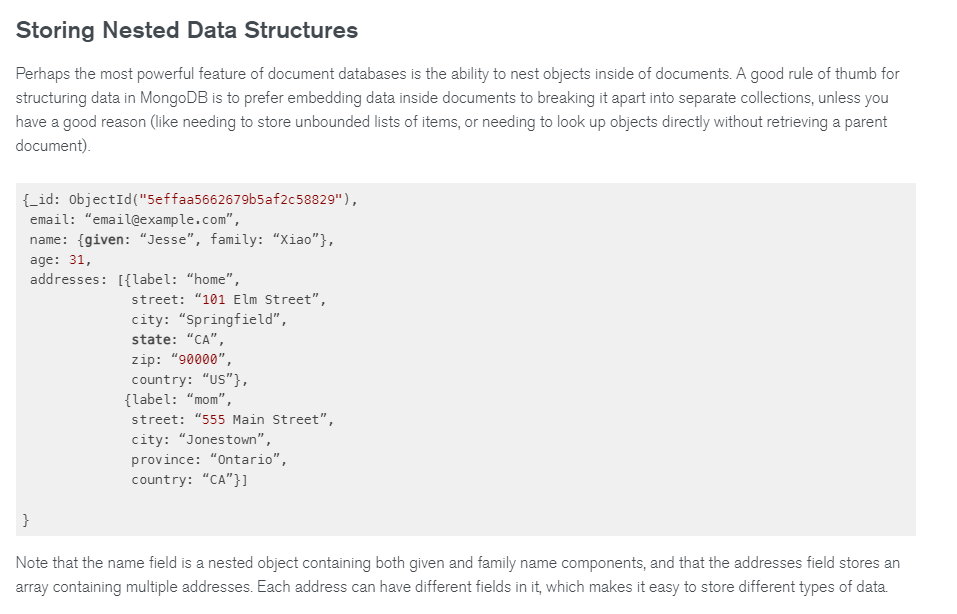
The overwhelming majority of problems that arise in working with data are laid in the early stages when a programmer chooses a database and an ORM and starts building models. Unfortunately, software developers often do not know how to do this normally. There are thousands of projects that are experiencing more and more data problems as they grow since many errors were committed by developers during the design phase. NoSQL databases were invented in the mid-2000s, and a huge number of people started experimenting with them. Some things immediately seemed strange to me: for example, the screenshot was taken from MongoDB, the most popular DBMS, and it shows work with relational structures. A large number of tutorials available on the Internet were written according to the following pattern: take MongoDB, insert JSON documents there, and everything will run like clockwork. But sometimes people insert relational JSON data there, for example, catalogs of movies. Yes, it will work fine, but only for the first time. If a system continuously accumulates data, then sooner or later we will face the fact that these relational structures will have to be processed in a relational way, and here JSON will be useless. As a result, such a project will be buried as early as at the database selection stage.
An example of relational structures from MongoDB
Limitations of NoSQL on the example of a project for a federal retail chain in Voronezh
Developers selected MongoDB at the earliest stage of the project. But they used it incorrectly: the data that was stored in it had a relational nature. The business logic of applications treated them as relational data, and MongoDB in this regard is much inferior to relational DBMS. And when the database grew to hundreds of gigabytes, the developers faced a problem: it was impossible to further increase its performance because of the data processing bottleneck. The DevOps engineer from this company said that at that time the budget was sufficient. They asked third-party companies to process some data when they needed to do it quickly, but no one could handle it. Nothing could help, neither adding servers nor sharding, because the developers have been tied to NoSQL from the very beginning. Ruslan Makhmudov, based on his own experience, states that NoSQL databases really show good results in different benchmarks, but they have a limited scope.
When is a NoSQL DBMS really needed?
Unstructured data, like logs, can be stored in NoSQL. If you work with raw data (readings of sensors or terminals), you can also accumulate them in NoSQL. There are a couple of other good use cases for NoSQL, but in the vast majority of cases, you will still be working with relational structures. Modern relational database management systems are compatible with JSON and support JSON search and indexing.
Critical errors
Implicit denormalization
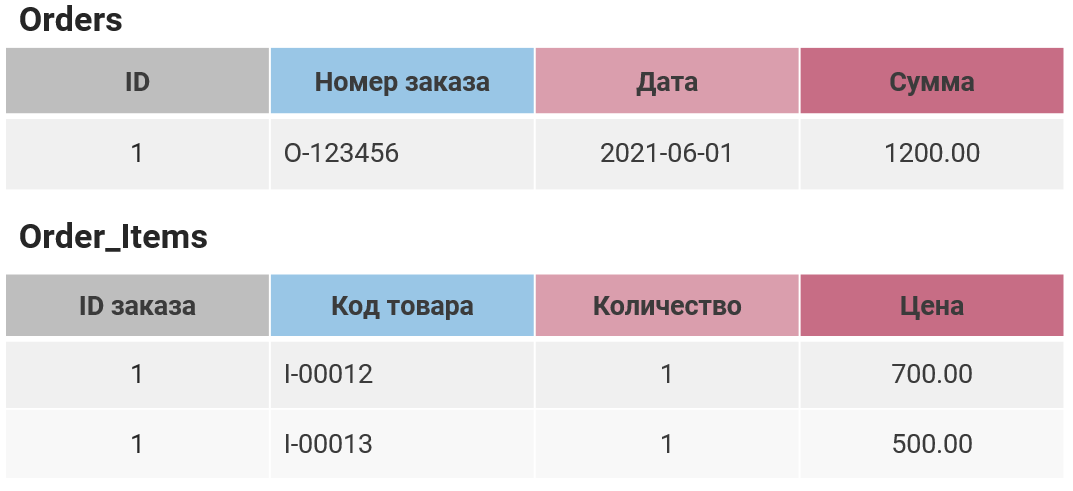
There is a quite common synthetic case: a table with the "Order Total" field is created for some order. Nevertheless, these orders in another table have detailed prices for each item, and if these items are summed up, you will also get the order total. Everything seems to be fine, but sooner or later, for a variety of reasons, the amounts in the two tables will start to differ. For example, this may happen when the app functionality will become more complicated and some new conditions will appear (discounts, affiliate programs, and returns of goods). These problems are common for the sales industry. At that moment, dissatisfied customers will begin to complain that their sums do not match, and it will be difficult to fix this since these numbers will appear throughout the entire database. You will start to lose money.
Float/double for the financial sector
If you work with money, never use data types such as float/double. This is no coincidence they are called "data types with floating precision". The screenshot shows several cases when the produced value does not meet your expectations: even an ordinary subtraction of two primes might lead to an inaccurate result. These real value types have a rounding problem, and they should never be used if you work with money because sooner or later an accountant will ask you why the sums are mismatching—and they will differ by dollars, not cents. Every database and every programming language have a special data type for financial calculations, which does not have such rounding problems.

Inappropriate data types
Developers sometimes use completely inappropriate data types for storing values. Even now, sometimes we encounter data types that are stored as a string (see the screen). Is "06.12.01" June 12, 2001, or December 6, 2001? Such things swamp the application business logic with a huge number of validations—and some errors are nevertheless inevitable. It is a bad idea to use "Y" and "N" characters in order to mark some binary value. It is better to use a boolean with the values true/false, because sooner or later, someone will make a mistake and type "y" in lowercase or in a different language, and then it will take a very long time to find the cause of the breakdown.
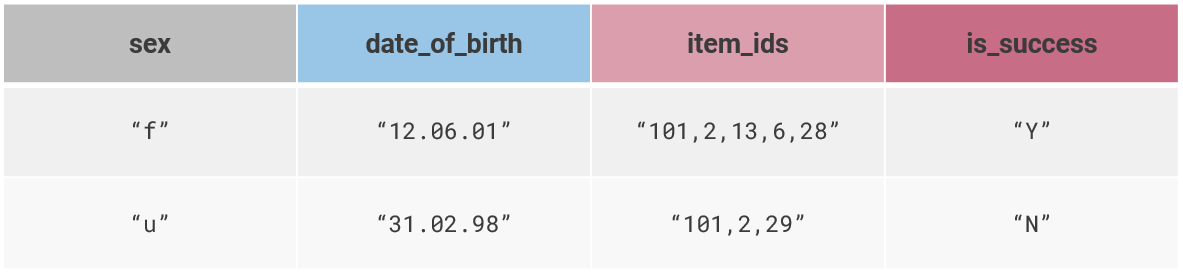
Storing numbers as a string
This is a regular problem. People somehow manage to store TIN, Insurance individual account number, BIC, and other data, which are essentially numbers, as a string. Citizen ID numbers, details of documents, and even bank accounts are also numbers. Storing data in a string is a waste of resources, and that's not even the worst trouble. The biggest problem is that people sometimes store data in a formatted form, and this is an unacceptable mistake not only when working with a database, but also when programming. Any application we write consists of three tiers: the presentation layer, business logic, and data manipulation. These tiers need to be separated so that one does not merge with another. But when you store the database values as needed for the presentation layer, it turns out that we are jumping over an entire layer.

Ruslan Makhmudov: “I remember a case when we had to store phone numbers in a string with a strict form, "+ 7xxxxxxxxxx" with a plus at the beginning and 11 digits after it. The corresponding table had a varchar field with a length of exactly 12 characters allocated for this type. That was a clear business requirement. This causes an insane waste of resources for a table with tens of millions of records, and, by the way, the phone number was often searched. It would be much smarter to convert everything to a number, which would both increase the query speed and reduce the amount of data. We tried to persuade the customer to refactor the code, but after the calculation of labor costs, this issue was always laid back... And then we had new customers from Finland, where phone numbers start with +3 and have 13 characters. As a result, we uploaded clients from Finland without phone numbers to our database, and we lost all of them at once. It was very difficult for us to get out of this mess."
0 or “” instead of NULL
Programmers sometimes do not know how to set up mapping in ORM, and when they lack some data, values like "0" or an empty string may appear in the database. But you need to understand that 0 is also a value. From a common-sense point of view, if you don't know a value, you should put a NULL there. If you store zeros or empty strings in places where there is supposedly no data, sooner or later, when you change any context, complicate the business logic, you will fail to understand whether zero is a real value or means no data.








